CWGK is working with Brumfield Labs of Austin, Texas, to build an annotation and entity management system that will allow CWGK to locate, identify, and link together every person, place, organization, and geographical feature in every CWGK document. The annotation application, MashBill, has been live since February 2017, and CWGK staff and Graduate Research Associates working remotely from eight university campuses across the country have (as of April 2017) identified nearly 5,000 unique entities which appear over 8,000 times in nearly 700 CWGK texts.
CWGK published a preliminary plan for MashBill in the fall of 2016, but with the system now up and running, this post will move through through each step of the annotation process with screenshots.
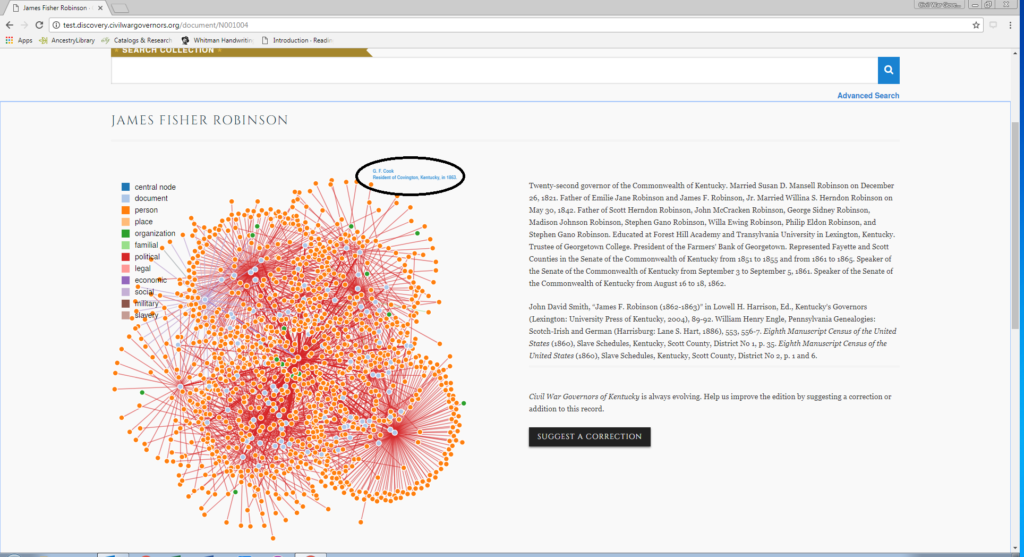
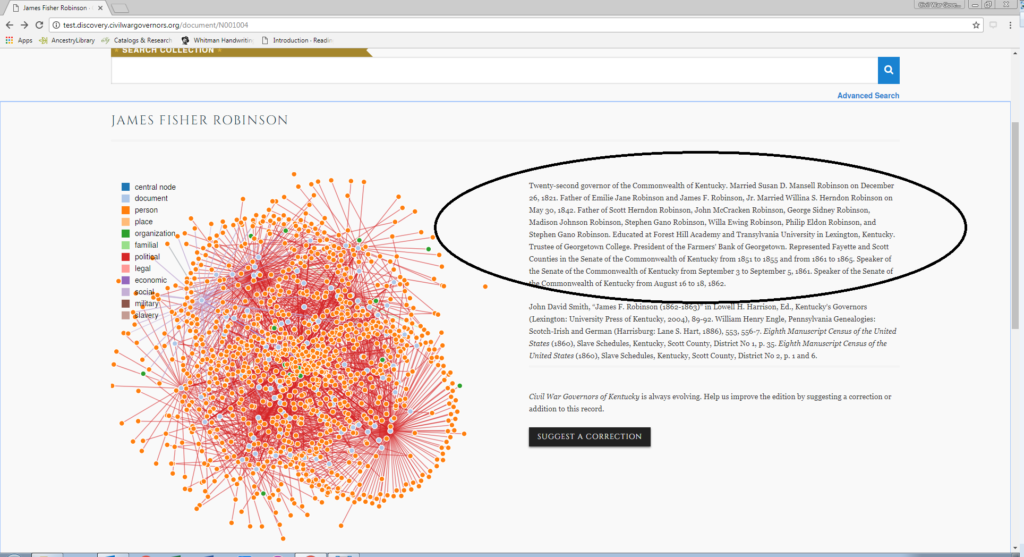
The first step is to search for and select the assigned document on the CWGK website.
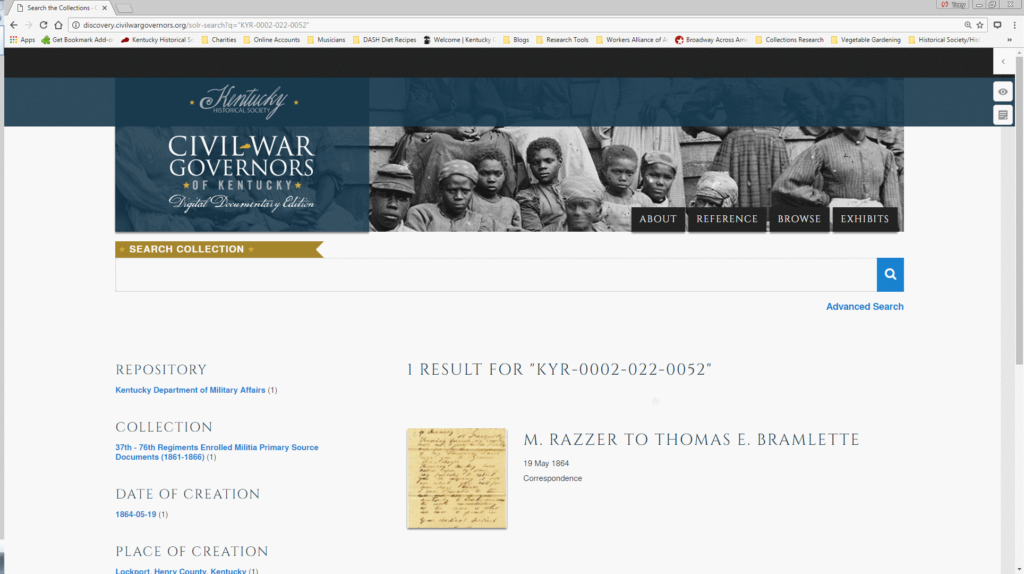
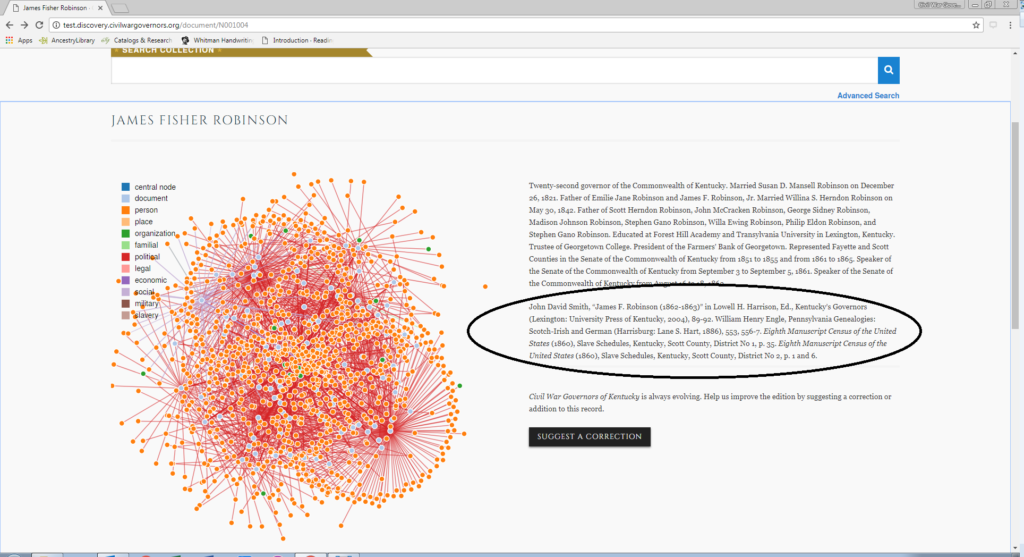
In the document view screen, the annotator activates a browser plugin called Hypothes.is, which enables annotation and commentary on any web page. All CWGK staff and GRAs are members of an invitation-only Hypothes.is group, which collects data and feeds it into the MashBill system.
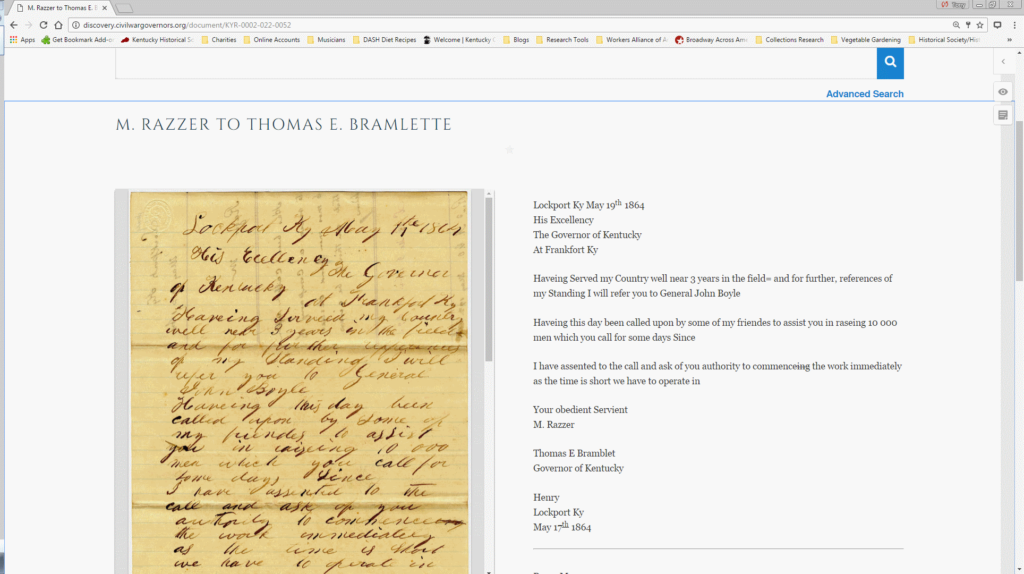
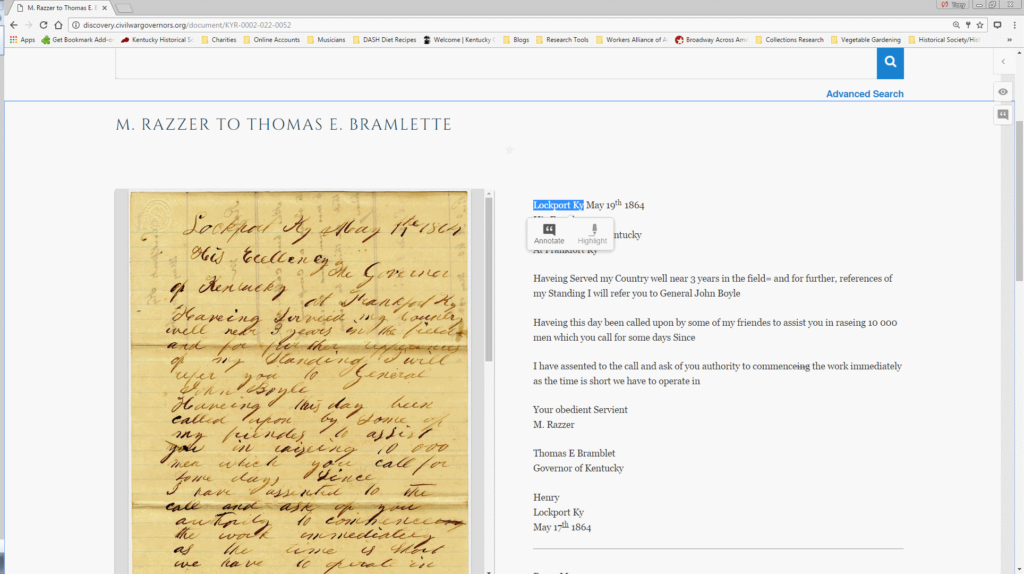
The next step is to highlight all entities (people, places, organizations, or geographical features) at their first mention in the text of the documents, select annotate when the Hypothes.is icon appears above the text, and click “Post to CWGK”.
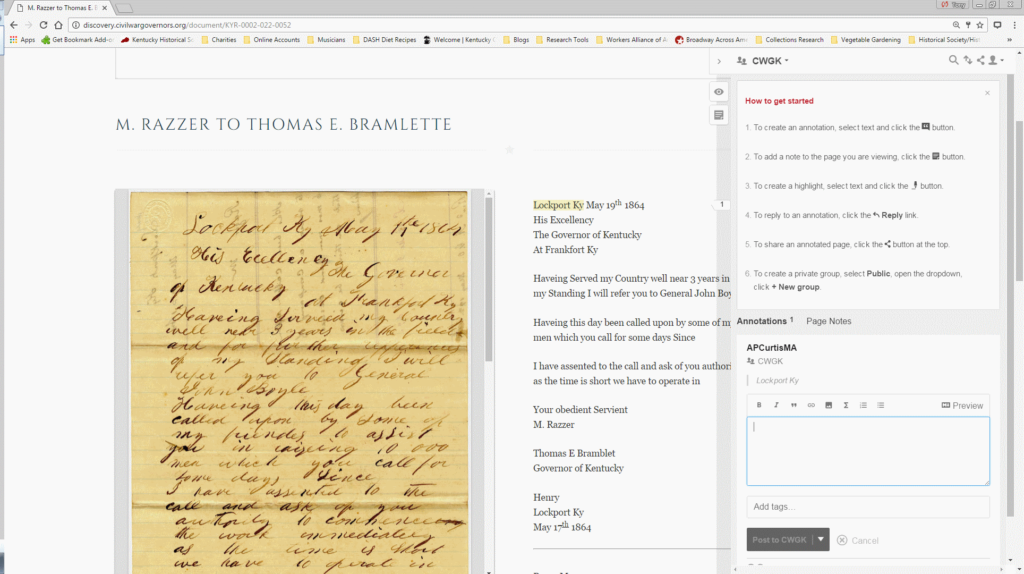
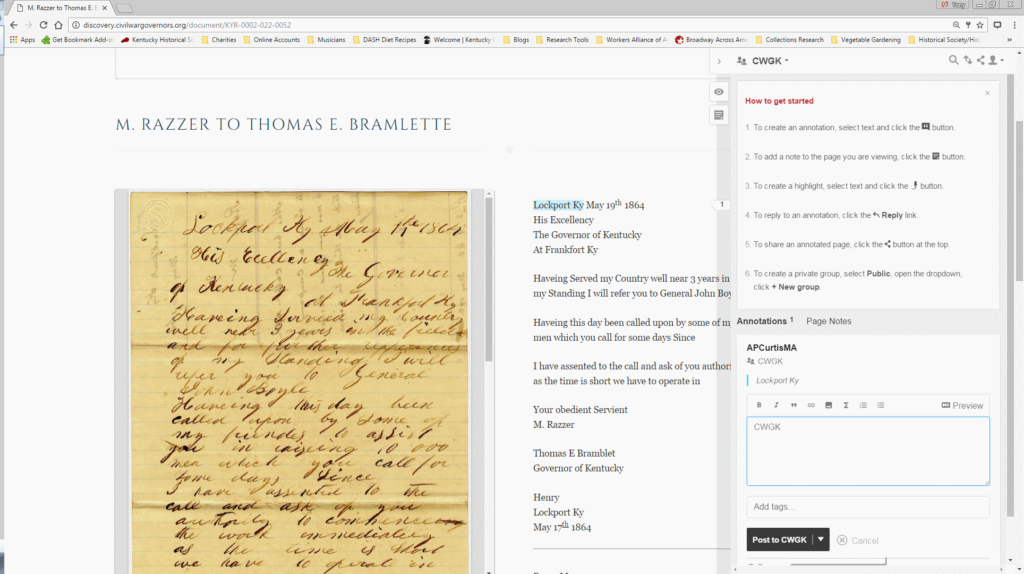
Once an annotator completes this process, they can click on the Hypothes.is icon in the browser toolbar to review all of the highlighted entities.
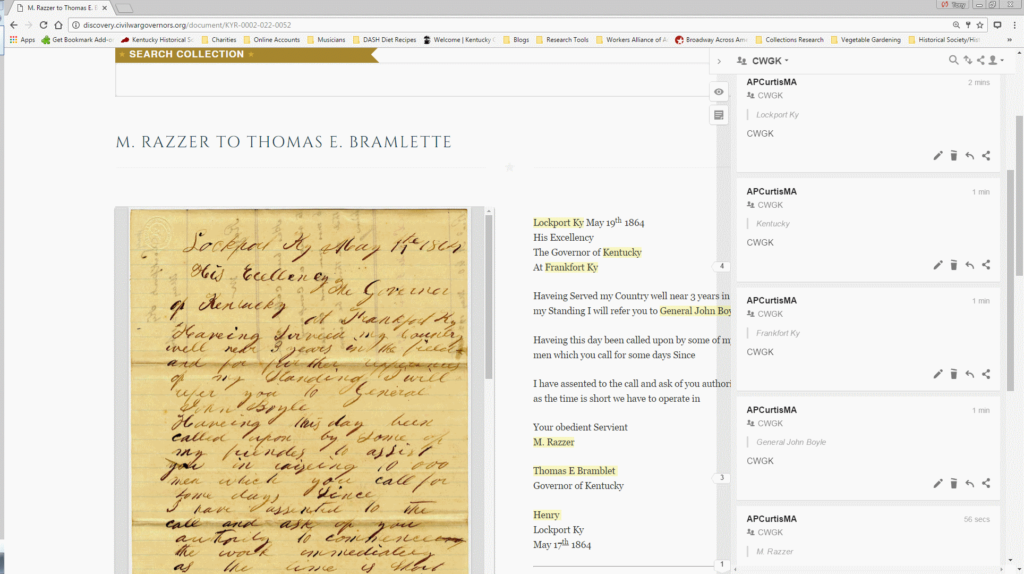
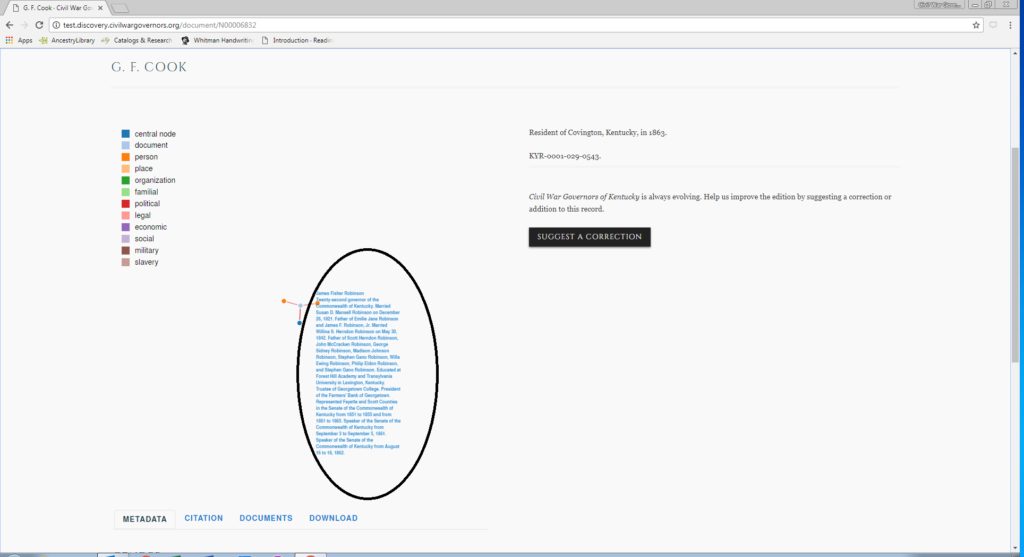
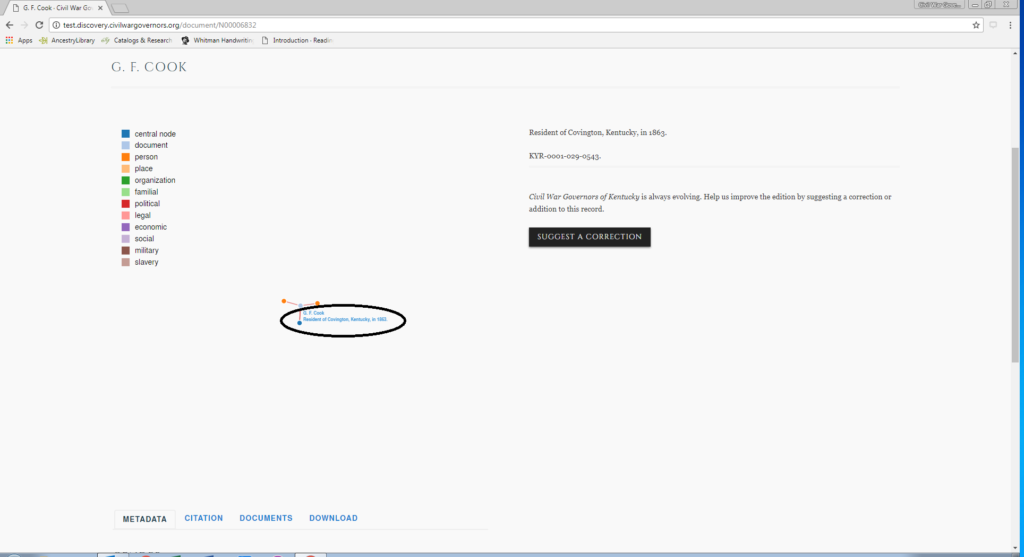
The annotator then moves into MashBill itself, where each user sees a dashboard of their own previous work, a running tab of the latest work in the database, and search fields to find an entity or document. Those search fields allow the annotator to look up the document number which has just been highlighted in MashBill.
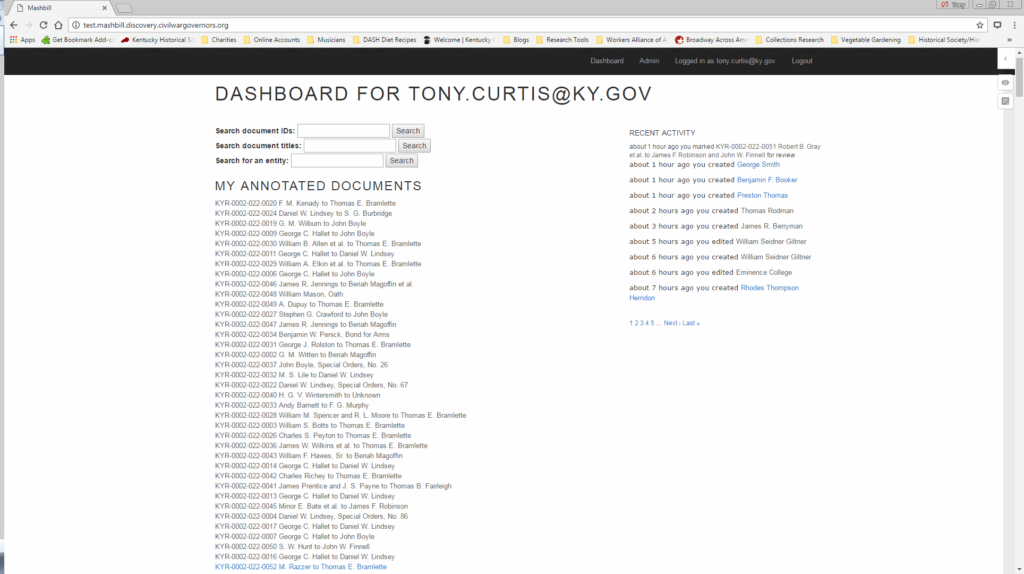
Each of the character strings highlighted in Hypothes.is appear on the MashBill document screen.
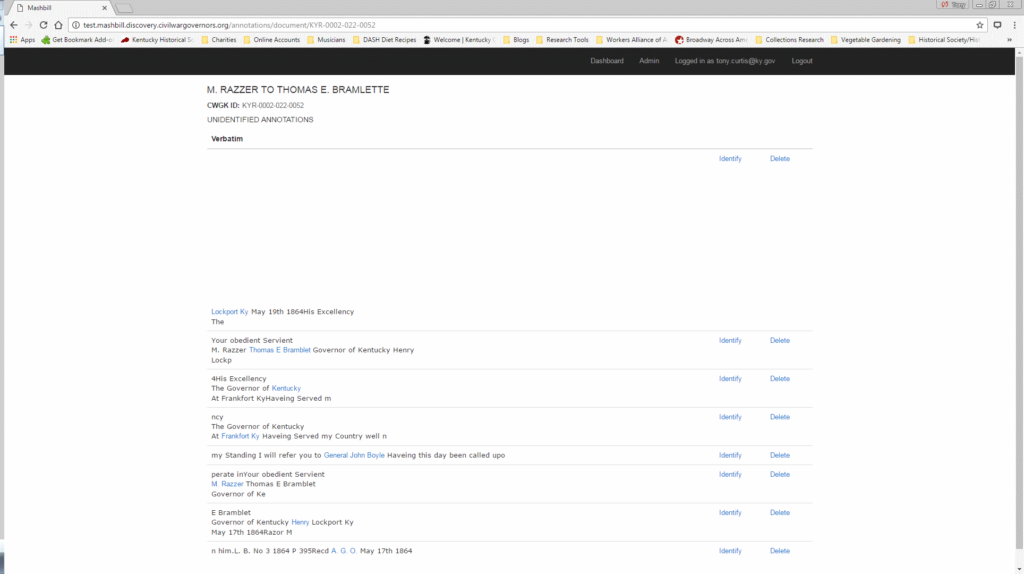
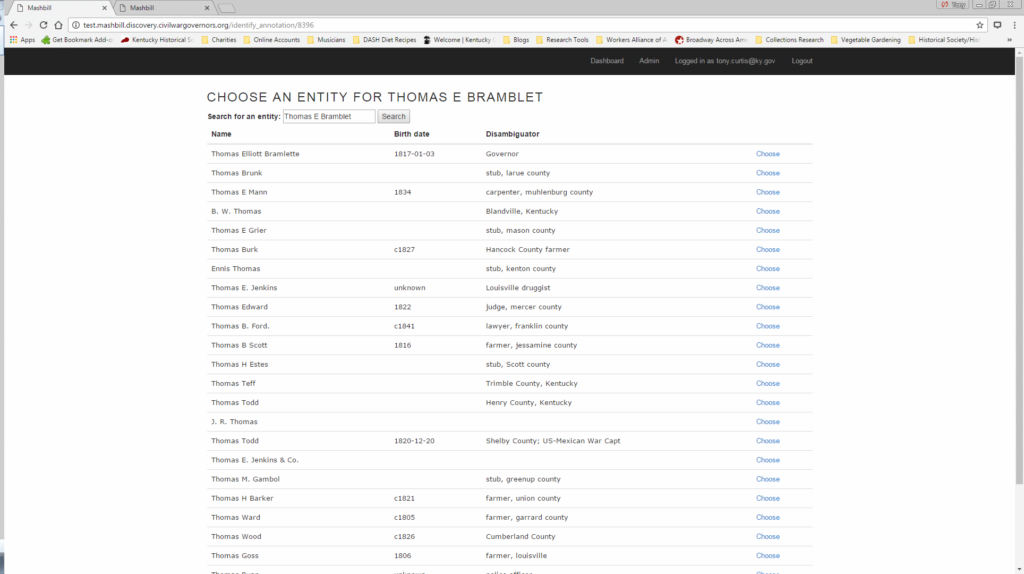
The user selects “identify” to search the database for entity names which are at least a 30% match to the transcribed character string. This degree of proximity suggests likely matches, but still allows flexibility to account for name abbreviations, misspellings, and the use of titles to identify individuals.
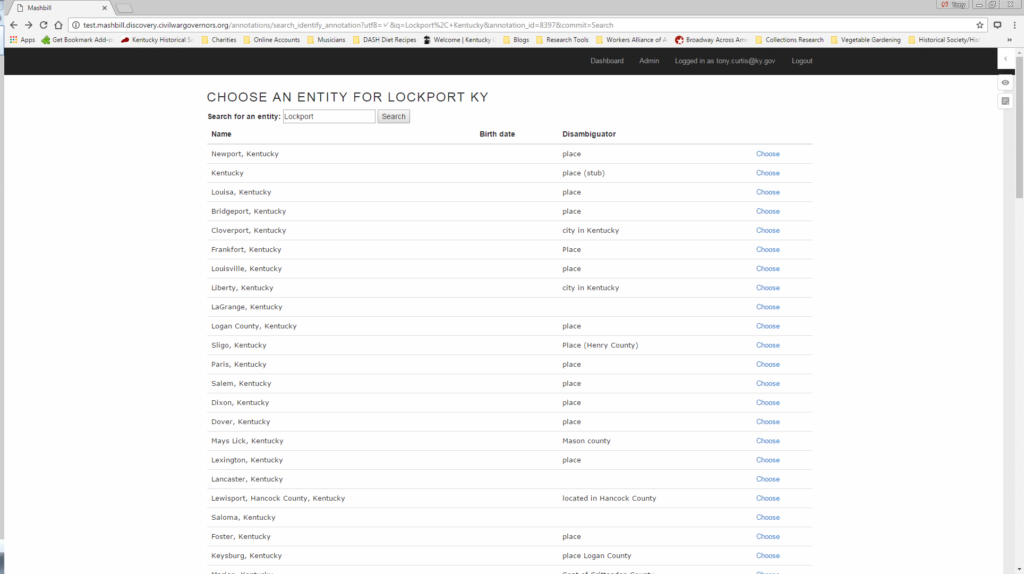
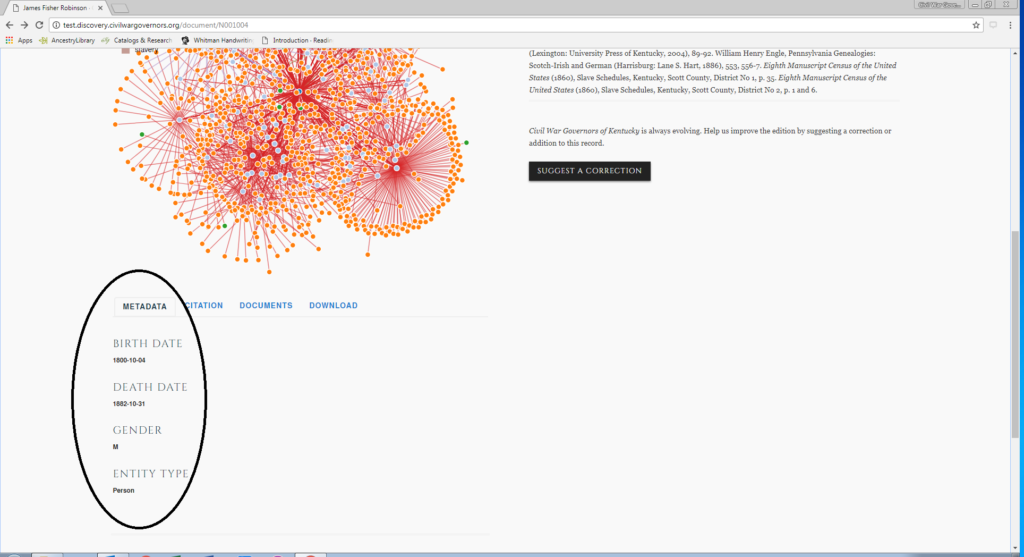
MashBill suggests known entities, but if the entity in question has not yet been added to the database, the annotator moves to the entity creation screen.
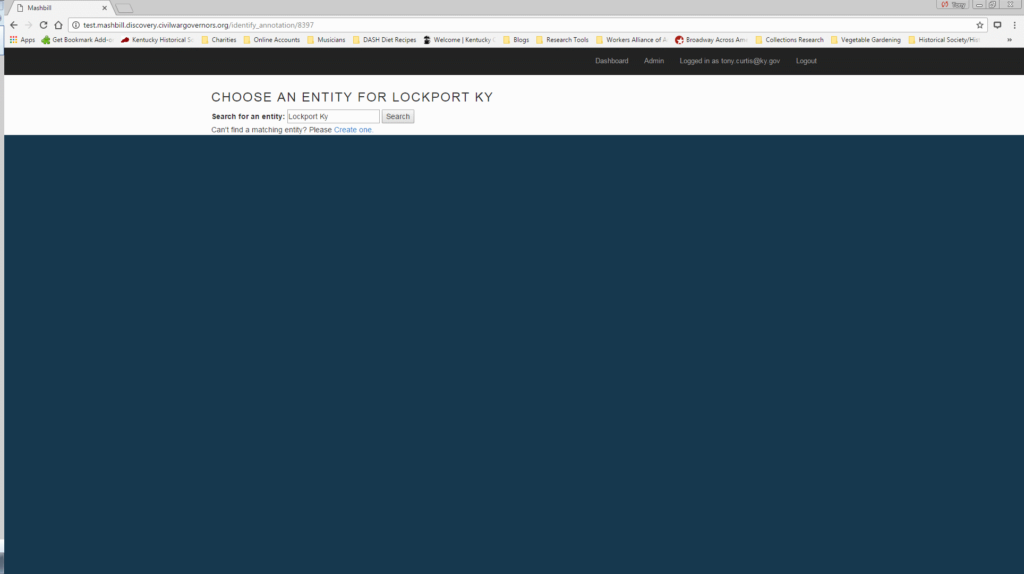
After research in approved, authoritative, and reliable sources, the annotator writes a short entity “biography”, fills out a bibliography section, marks up any textual features including italics and underlining in Markdown, and fills in the metadata fields relevant to the entity type.
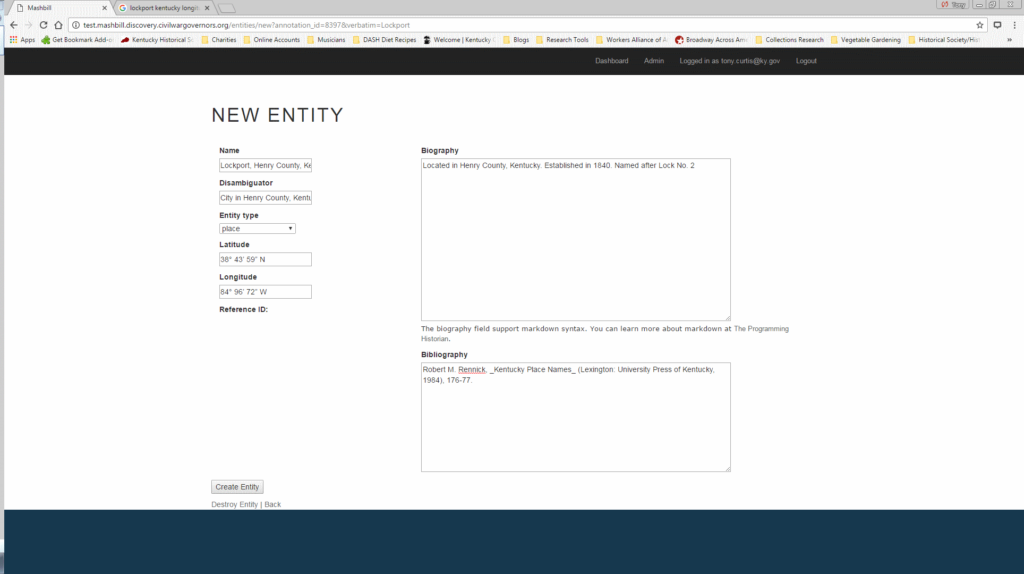
The annotator confirms the information is correct and creates the entity, which is automatically linked to the character string highlighted in Hypothes.is.
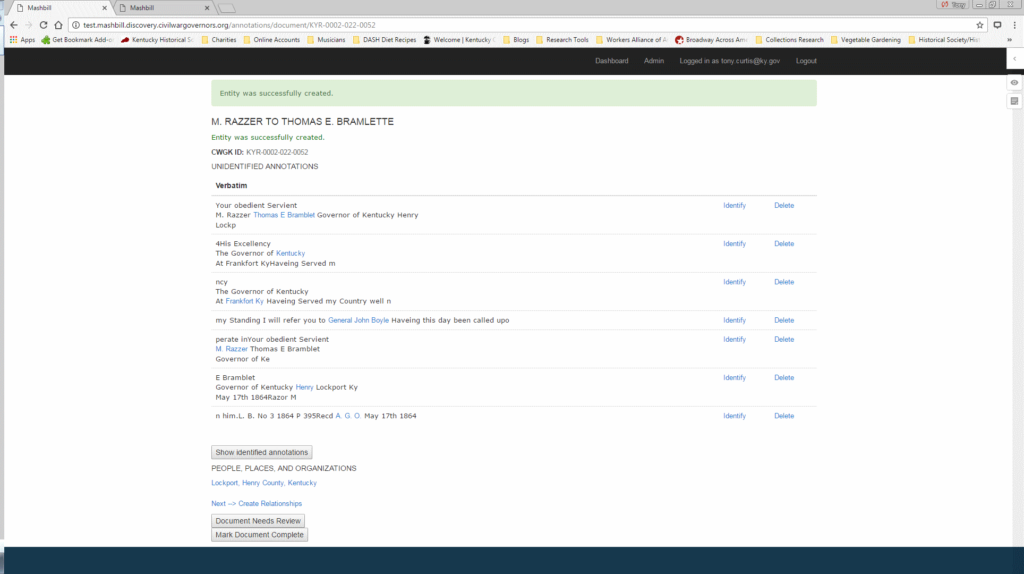
If an entity already exists in the MashBill database, the user simply chooses the correct entity from the suggested list and MashBill automatically links the entity record to the character string.
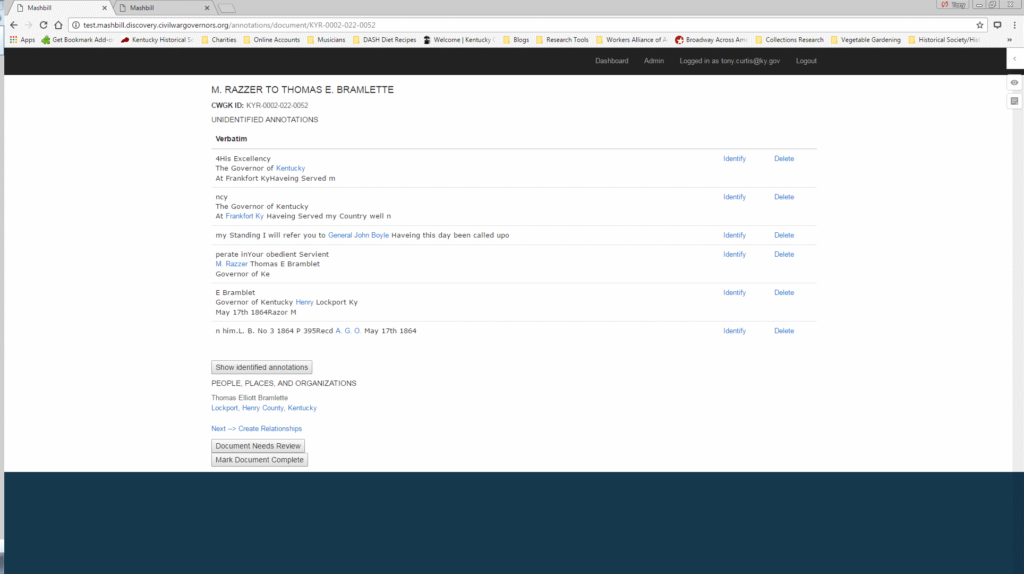
The annotator proceeds until all of the entities for the document have been identified. They then click “Document Needs Reviewed” which sends the document into the fact-checking queue.
When another staff member checks work for accuracy and adherence to editorial style, the document will be marked complete, and MashBill will insert reference tags containing the unique identifier for each entity biography into the TEI-XML transcription of the document stored in GitHub. These files will be re-imported into the existing CWGK Omeka site along with the entity biographies, allowing hyperlinked navigation between text and biography.
The final step in the current CWGK annotation process is social networking, documenting all of the relationships between individuals and organizations present in the text of the document itself.
Each relationship between entities is classified as one of a handful of types: familial, political, legal, economic, social, military, and slavery. Entities can have multiple relationships within documents if the relationship between the two is multifaceted or evolves as the document proceeds. Entities can also have the same type of relationship documented in multiple documents, adding weight to the vector between those two nodes. entities can be involved in a complex network of relationships.
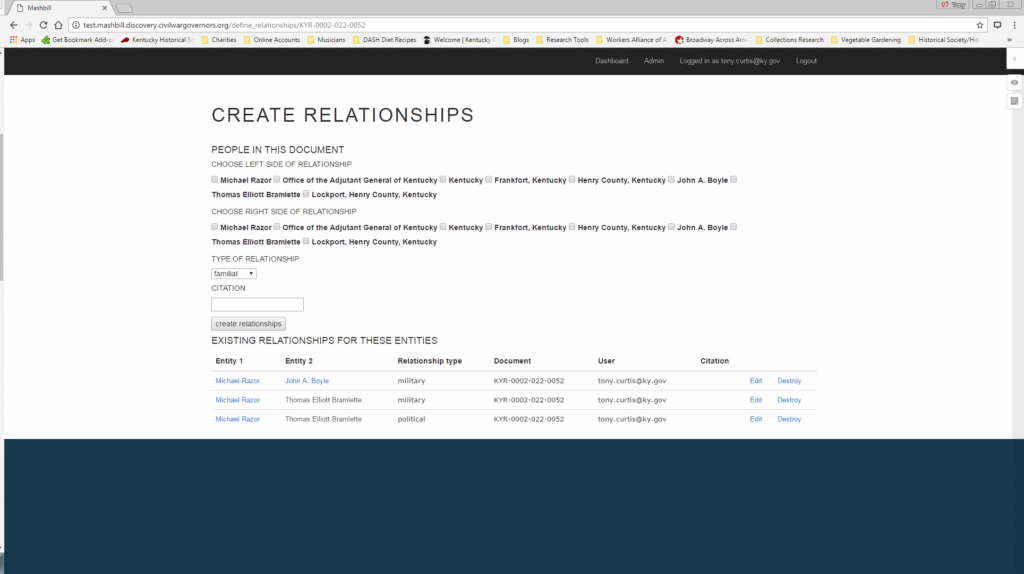
When the relationships have been identified and created, the annotation stage on this document is complete and the annotator moves on to the next assignment.